
Механизм работы Web-сервера
Определив понятие языка HTML, можно более подробно описать механизм работы Web-сервера и браузера. Рассмотрим пример обращения к ресурсу www.translate.ru (рис. 4.12).
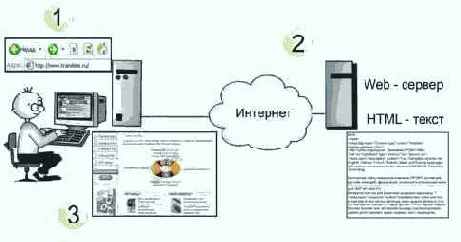
Рис. 4.12. Схема работы Web-сервера
В адресной строке браузера набираем необходимый URL (рис. 4.12, пункт 1), после чего браузер получает информацию об используемом протоколе (http) и имени сервера (www.translate.ru). Браузер устанавливает связь с искомым Web-сервером и, используя протокол HTTP, запрашивает искомый ресурс. Сервер посылает браузеру HTML-страницу, которая хранится на сервере (рис. 4.12, пункт 2).Обычно даже простая Web-страница содержит не только текст, но и графику, т.е. состоит из нескольких файлов разного типа. Браузер считывает HTML-тэги, воссоздает страницу на экране компьютера, и мы видим результат своего запроса (рис. 4.12, пункт 3).
В данном случае мы рассмотрели пример работы так называемых статических страниц.
Статические страницы представляют собой точную копию файлов, лежащих в каталогах Web-cервера, и не изменяются до тех пор, пока разработчик сам в них что-то не поменяет. Однако страницы могут формироваться динамически, т.е. во время обработки запроса по какой-то программе, а не из готового файла на диске. Вы наверняка сталкивались со страницами, которые были созданы по вашему запросу динамически,- как говорится, "сформированы на лету". Например, любая книга отзывов на Web-сайте предоставляет определенную форму, в которую вы добавляете свой текст, когда вы в следующий раз открываете эту страницу, она содержит новое сообщение.
Аналогично, когда поисковой машине дается запрос по поводу некоторого документа и она выдает список ссылок, очевидно, что этот список формировался именно на данный запрос, а не хранился в Сети заранее.